FlashAttention升级,实现长文本推理速度8倍提升
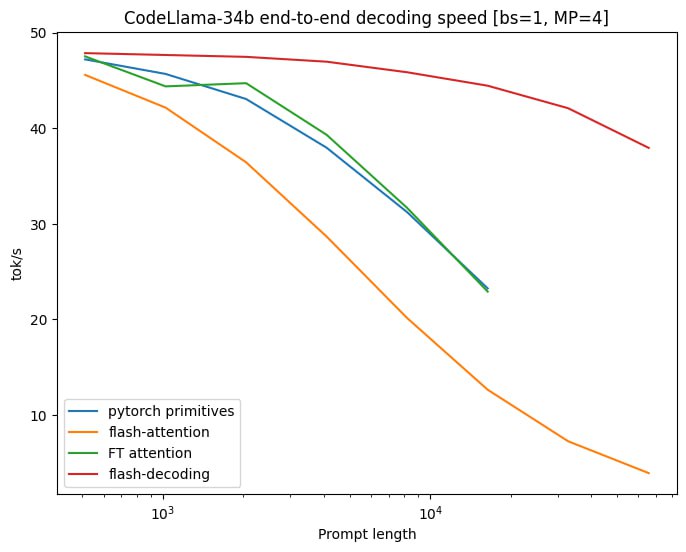
Together AI官方推特发文称其推出的Flash-Decoding,使长上下文 LLM 推理速度加快8倍。
据其介绍,达成这一效果的原理为并行加载KV缓存,然后分别重新缩放以合并结果。
投稿:@ZaiHuaBot
频道:@TestFlightCN

Telegram 评论区
0 条回复,可以前往 Telegram 继续讨论。
Together AI官方推特发文称其推出的Flash-Decoding,使长上下文 LLM 推理速度加快8倍。
据其介绍,达成这一效果的原理为并行加载KV缓存,然后分别重新缩放以合并结果。
投稿:@ZaiHuaBot
频道:@TestFlightCN
Telegram 评论区
0 条回复,可以前往 Telegram 继续讨论。